
Key Takeaways
- Machine learning is a subset of AI, while deep learning is a specialized branch of machine learning.
- The main types of machine learning are supervised, unsupervised, and reinforcement learning.
- Machine learning follows a structured process, starting with data collection and preprocessing, then model selection and training, followed by testing and evaluation to ensure accurate pattern recognition and predictions.
We are surrounded by machine learning-based technology—search engines somehow know just what we’re looking for, email filters keep our inboxes clean, cameras adjust to capture faces in perfect focus, and fraud detection systems flag suspicious transactions before we even realize something’s wrong.
Machine learning makes it possible for technology to adapt, predict, and continuously improve without the need for human intervention at each step. But what is machine learning exactly, and how does it work? The answers are necessary to decide if this field is the right fit for you.
What Is Machine Learning?
Machine learning refers to the process by which computers are able to recognize patterns and improve their performance over time without needing to be programmed for every possible scenario. Instead of following a rigid set of rules, these systems analyze data, make predictions, and adjust their approach based on their learning.
This adapting ability makes machine learning one of the most powerful tools in modern technology. Thanks to it, computers can perform tasks that once required human intuition—like identifying objects in images, understanding spoken language, or detecting fraudulent transactions.
Though the concept might seem like a product of modern advancements, the idea has been around for decades. In 1959, Arthur Samuel, one of the pioneers in computer science, defined it as “the field of study that gives computers the ability to learn without being explicitly programmed.” This means that instead of relying on fixed rules, machine learning systems develop their own insights by analyzing vast amounts of data and adjusting accordingly.
This idea was later reinforced by Herbert Simon, considered a founding father of artificial intelligence, who explained that machine learning is fundamentally about improving performance through experience—just as humans get better at tasks through practice.
Machine Learning Versus Other Similar Fields
Machine learning is intertwined with many other fields that deal with data, computing, and intelligent decision-making. It shares strong connections with artificial intelligence, data science, deep learning, robotics, natural language processing, and many others.
Machine learning vs. deep learning
Deep learning is a branch of machine learning that focuses on the use of layered neural networks—often called deep neural networks—to process data in sophisticated ways. While both aim to teach machines to recognize patterns and improve performance, deep learning is a more specialized and advanced version.
In traditional machine learning, humans still need to tell the computer what features to focus on. For example, if you’re training a model to recognize cats in pictures, you might have to manually tell it to look at specific features like the shape of the ears.
Deep learning removes this manual step using neural networks, a type of computer system designed to work similarly to the human brain. These networks have multiple layers, allowing them to automatically find and refine features on their own.
However, deep learning needs a lot more data and computing power to work well, unlike traditional machine learning, which can work with smaller datasets.
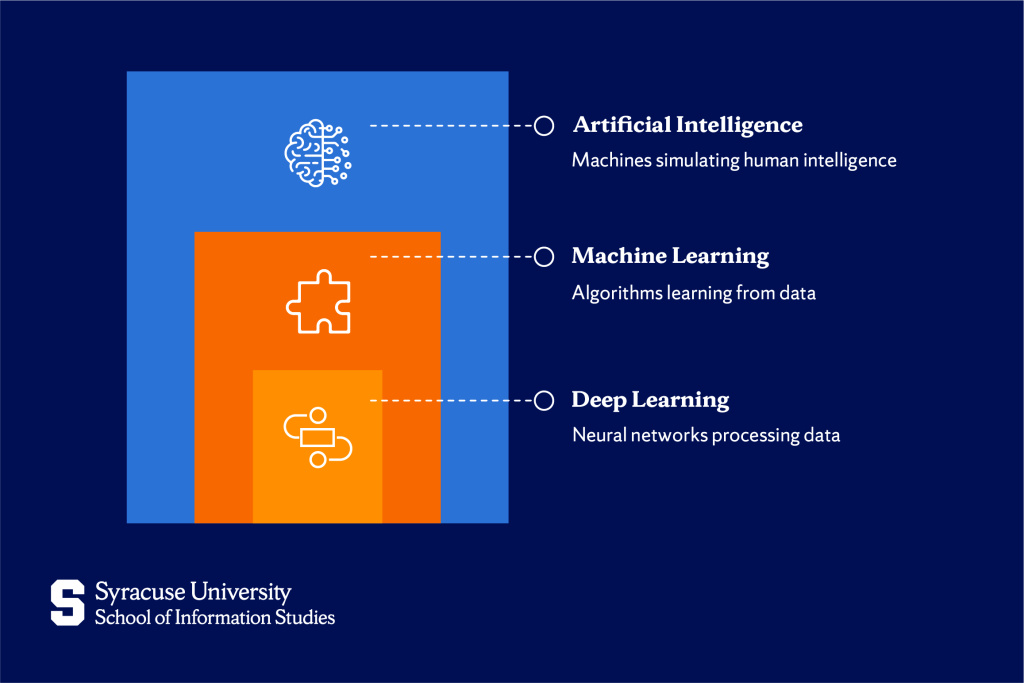
Machine learning vs. artificial intelligence
Machine learning is part of artificial intelligence (AI), as the latter is a much broader concept. AI is all about creating systems that can simulate human-like thinking and problem-solving through logic-based programming, expert systems, or machine learning techniques. Machine learning is one of the ways AI achieves this.
Data science relates to both AI and machine learning by providing the structured data and analytical techniques that fuel them. It prepares the data that machine learning learns from. Then, AI uses those machine learning models to automate and make decisions.
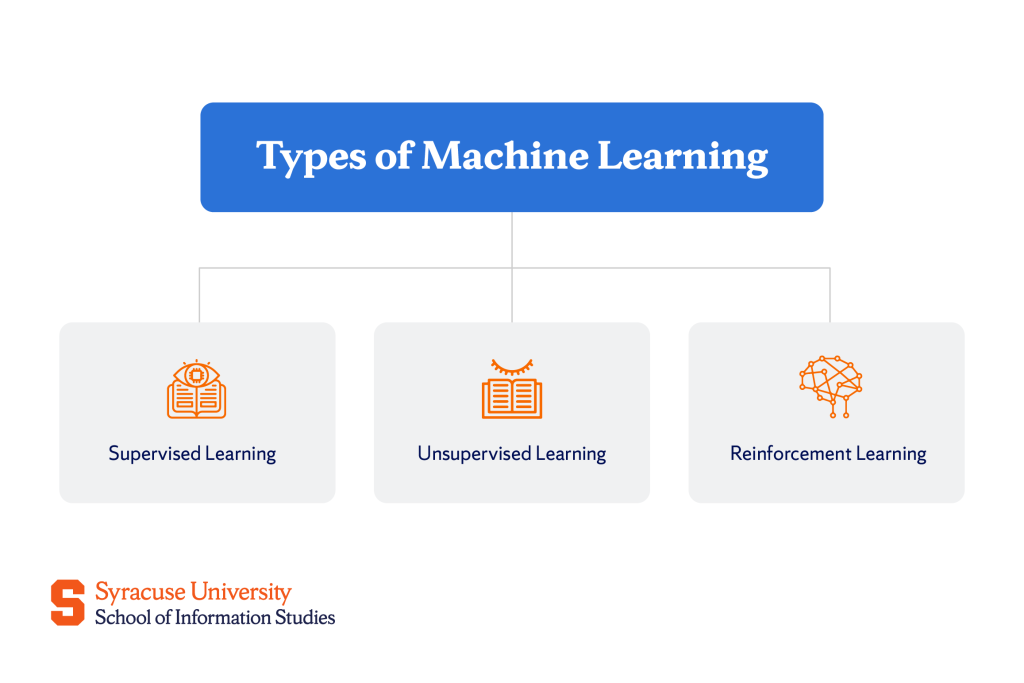
Types of Machine Learning
Not all machine learning models work the same way—different approaches exist since there are different problems to deal with. The top three types of learning include:
Supervised learning
Supervised learning works like learning with a tutor who provides the correct answers. The system is trained on data that comes with labels, meaning the correct outcome is already known. By recognizing patterns in labeled data, the model learns to make predictions on new data.
For example, an email filter can be trained to detect spam by being provided with thousands of emails labeled as either spam or not spam. By analyzing these labeled examples, the model learns which words, phrases, or senders are commonly associated with spam and applies this knowledge to filter incoming messages. This method is widely used in speech recognition, medical diagnosis, fraud detection, and product recommendation systems.
Unsupervised learning
Unsupervised learning takes a different approach—it works without labeled data, meaning the system must identify patterns and relationships on its own. Instead of being told what to look for, it processes large amounts of data and organizes it based on similarities or differences.
One example is anomaly detection in emails. Without prior labels, the system analyzes thousands of “normal” emails and learns what a typical email looks like. When a new email arrives that doesn’t fit the usual pattern—perhaps containing unusual wording, suspicious links, or an unfamiliar sender—it flags it as potentially fraudulent. Unsupervised learning is often used for fraud detection, customer segmentation, and content recommendations, where patterns emerge naturally from the data.
In certain cases, there can also be semi-supervised learning, which combines aspects of both supervised and unsupervised learning—the model first learns from the small labeled dataset and then improves its accuracy by identifying patterns in the much larger unlabeled dataset.
Reinforcement learning
This type of learning is based on trial and error. Instead of learning from a fixed dataset, the system interacts with its environment, makes decisions, and receives feedback through rewards or penalties. Over time, it refines its strategies to maximize positive outcomes.
A self-driving car is a good example. It does not have a predefined set of instructions for every possible situation it may encounter on the road. Instead, it learns by trying different actions, such as accelerating, braking, or turning, and observing the results. When an action brings it closer to safe and efficient driving, it is reinforced as a good choice. Reinforcement learning is widely used in robotics, stock market predictions, and optimizing logistics.
How Does Machine Learning Work?
While the specific approaches taken can vary, most machine learning models follow a similar workflow that starts with gathering data and ends with algorithms that can easily recognize patterns and make predictions as needed.
It all begins with data collection, where large amounts of information are gathered. The data can be collected from various sources, such as online transactions, customer interactions, sensor readings, medical records, and more.
Once the data is collected, the data undergoes preprocessing. This step guarantees the information passed to the next stage is clean and structured by eliminating duplicate entries, filling in missing values, standardizing numerical data, and converting categorical variables into a machine-readable format.
With clean and structured data in hand, model selection and training begins. As stated, the choice of model depends on the specific task, as different algorithms specialize in different types of problems. Training the model involves feeding it data and adjusting its internal parameters so that it learns to make accurate predictions. The more relevant examples it is given, the better it gets at identifying patterns and making decisions.
However, even if a model performs well during training, that doesn’t necessarily mean it’s ready to be used in real-world applications. To confirm it can handle unseen data, it must undergo testing and evaluation. Therefore, a separate dataset—one the model hasn’t encountered before—is used to measure how well it responds to new information rather than simply memorizing past examples. Performance is assessed using different metrics depending on the task.
Beyond the model itself, no matter how advanced an algorithm is, without high-quality data and well-crafted features, it won’t deliver useful results.
Machine Learning Algorithms
Machine learning algorithms come in a variety of forms—some are quite straightforward and easy to interpret, while others are more complex and require additional computational resources. The choice between them depends on the problem being solved, the type of data available, and the level of accuracy required.
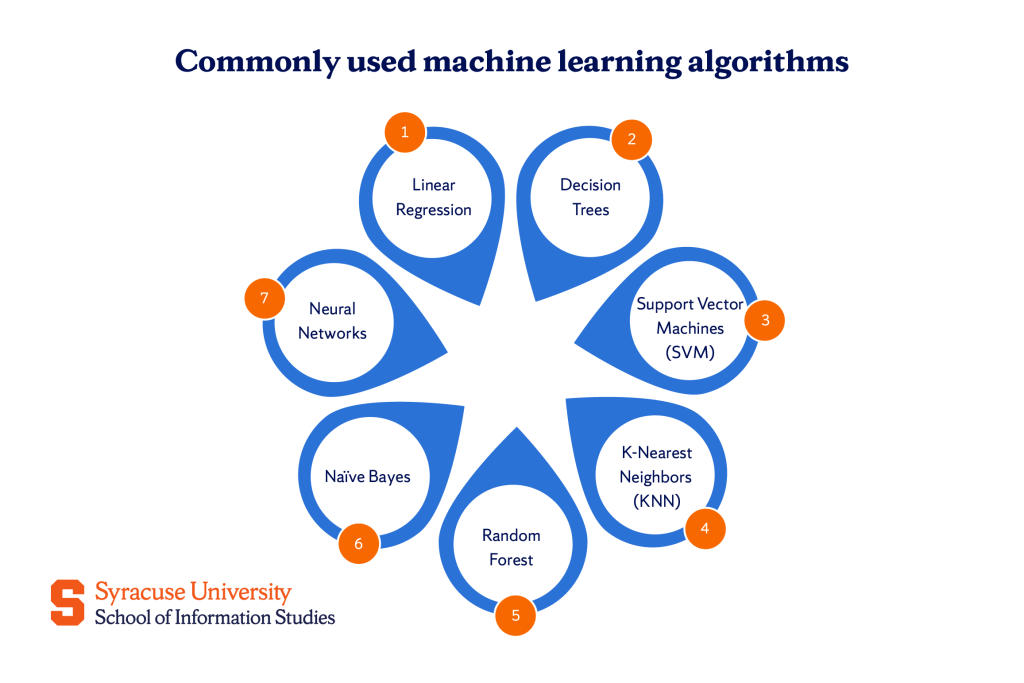
Some of the most commonly used machine learning algorithms include:
Linear Regression
Linear regression is one of the most widely used machine learning algorithms for predicting numerical values. It works by finding the best-fitting straight line (or hyperplane in higher dimensions) that describes the relationship between input variables (features) and an output variable.
Decision Trees
Decision trees are intuitive, rule-based models that split data into branches based on yes/no questions, ultimately leading to a decision. The tree starts with a root node that represents the entire dataset, and as it branches out, it makes sequential decisions based on different features.
Support Vector Machines (SVM)
Support Vector Machines (SVM) are powerful classification algorithms that work by finding the optimal boundary (or hyperplane) that best separates different categories in a dataset. The goal of an SVM is to maximize the margin between different classes, ensuring that new data points can be classified with high accuracy.
K-Nearest Neighbors (KNN)
K-Nearest Neighbors is a classification and regression algorithm that assigns a label to a new data point based on the majority class of its closest neighbors. It doesn’t explicitly learn from training data but memorizes the dataset and makes predictions based on similarity.
Random Forest
Random Forest is an ensemble learning method combining the output of multiple decision trees to produce a single result. Instead of relying on only one decision tree, Random Forest trains many trees on random subsets of data and averages their outputs (for regression) or selects the majority vote (for classification).
Naïve Bayes
Naïve Bayes is a probability-based classification algorithm that assumes all features are independent, even though this may not always be the case in real-world scenarios. It applies Bayes’ theorem to calculate the likelihood that a data point belongs to a specific category based on prior knowledge.
Neural Networks
Neural networks, commonly referred to as artificial neural networks, are inspired by the structure of the human brain and consist of layers of interconnected nodes (neurons) that process and transform data. They are particularly powerful in deep learning applications, where large amounts of data need to be analyzed for patterns.
Pros and Cons of Machine Learning Algorithms
Like any field that pushes the boundaries of technology, machine learning also comes with both advantages and some challenges. It provides excellent results, but the work to get those isn’t always the easiest.
Some of its most notable advantages include:
- Scalability and automation, as machine learning models can process large amounts of data at high speeds and handle repetitive tasks without constant human intervention.
- Enhanced decision-making with data-driven insights, allowing organizations to analyze patterns, detect trends, and make more informed choices.
- Potential to solve complex problems, enabling breakthroughs in different fields.
Alongside those, some of the biggest challenges include:
- Data dependency and quality concerns, including any inaccuracies, biases, or missing information. They can impact performance and reliability.
- Overfitting and underfitting, where a model may either become too specialized to its training data and fail to generalize well to new inputs or be too simplistic, missing important patterns and leading to poor predictions.
- Ethical and privacy issues, such as the use of sensitive personal data in machine learning. These raise concerns about bias, fairness, transparency, and potential misuse.
Real-World Machine Learning Applications Across Industries
From predicting what you’ll buy next to diagnosing diseases with greater accuracy, machine learning has found use everywhere. Its application has brought significant improvement in the following industries:
Healthcare
By analyzing patient records, genetic data, and medical imaging, machine learning models can detect patterns that may not be apparent to human doctors, leading to earlier identification of conditions like cancer, heart disease, and diabetes.
Such algorithms also help tailor treatments to each patient. Algorithms that analyze how different people respond to medications can optimize dosages, predict potential side effects, and suggest the most effective treatment plans.
Hospitals also often use machine learning for predictive analytics in order to estimate patient admission rates and optimize staff allocation for better care.
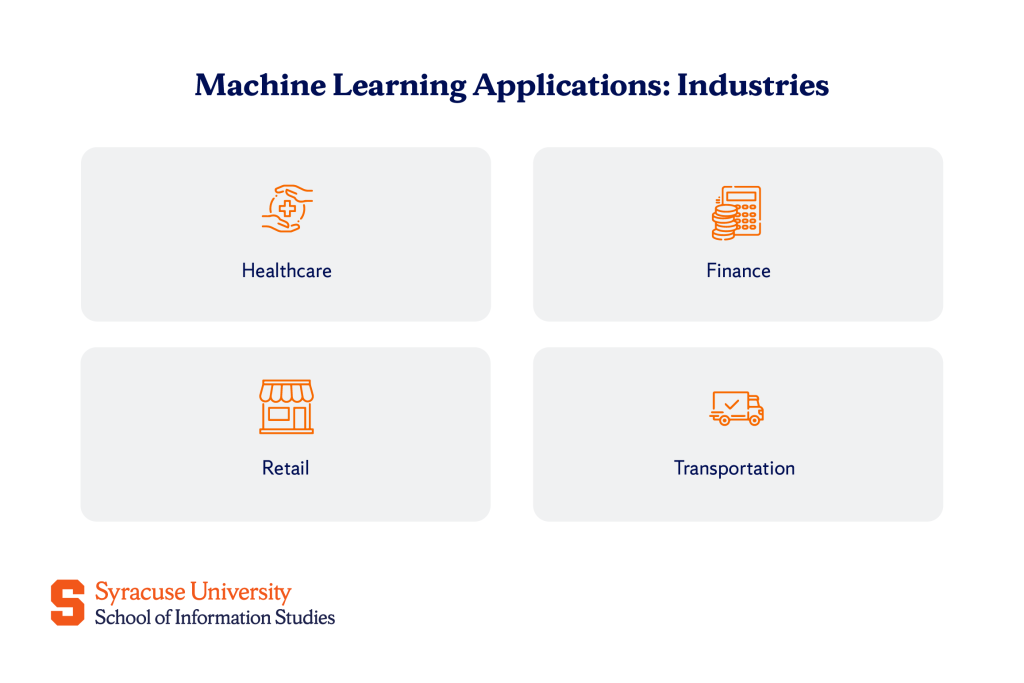
Finance
Machine learning is used in security systems to analyze millions of transactions in real time and then flag suspicious activity based on unusual spending behavior.
Credit scoring also benefits from machine learning. Traditional credit evaluation relied on a handful of financial factors, but modern machine learning models assess a wider range of data, including spending habits and transaction history, to determine a borrower’s creditworthiness more accurately.
Banks and investment firms also use machine learning for market analysis and automated trading, where algorithms predict stock trends and execute trades at lightning speed, optimizing investment portfolios with minimal human intervention.
Retail
E-commerce platforms use machine learning for recommendation systems to analyze browsing history, past purchases, and even how long potential customers linger on a product page to suggest items tailored to their preferences.
It also improves inventory management by analyzing buying trends, seasonal shifts, and supply chain data so it can predict demand and avoid overordering or running out of inventory.
Customer service chatbots powered by machine learning have also become a trend. They provide instant assistance to clients without the need for human intervention.
Transportation
Self-driving cars, a wonder of the 21st century, rely on deep learning models, as a specialized form of machine learning, to process sensor data, recognize road conditions, and make real-time driving decisions. These systems improve with experience, learning from millions of miles driven to navigate safely and efficiently.
Another key application is predictive maintenance, where machine learning models can analyze vehicle performance data to detect potential mechanical failures before they occur.
Machine Learning: A Tool, a Field, and a Future
Machine learning is everywhere. Its impact only continues to grow, and with it, so does the demand for those who understand how to use its power, refine its capabilities, and push the limits of what’s possible.
If you’re interested in pursuing a career in this field, Syracuse University’s iSchool provides the perfect starting point. You can begin exploring the fundamentals through our Applied Data Analytics Bachelor’s Degree and the Applied Data Analytics Minor. Alternatively, you can explore our Master’s in Artificial Intelligence or the one in Applied Data Science. All programs are designed to equip you with the knowledge, tools, and hands-on experience that is needed to make an impact in this field of work.
Machine learning may have the ability to adapt and improve on its own, but it still depends on the people who build, train, and guide it. So join us, and you might be the one to achieve the next breakthrough.
Frequently Asked Questions (FAQs)
What are the benefits of machine learning?
Its benefits include enhanced efficiency, automated complex tasks, improved decision-making with data-driven insights, personalized experiences, and innovation across industries.
Can I learn machine learning online?
Technically, yes. However, a structured university education offers something those courses can’t: a well-rounded foundation, hands-on experience, mentorship from experts, and the opportunity to work on real-world projects.
Is a university degree necessary to become a machine learning engineer?
Yes, most machine learning engineers hold degrees in artificial intelligence, computer science, or related fields, as these programs provide the necessary technical knowledge, mathematical foundations, and practical training required by employers.