
Key Takeaways
- The three core types of big data based on how information is organized and stored are structured, semi-structured, and unstructured data.
- Emerging forms of big data include streaming data, IoT sensor data, and clickstream data, which introduce continuous and real-time information flows.
- Understanding the different types of big data helps organizations choose appropriate technologies, manage information responsibly, and interpret data from multiple sources more effectively.
Every second, enormous amounts of data move through the world’s systems. Hospitals record patient histories, factories track equipment performance, financial markets generate transaction logs, and millions of people post updates, photos, and messages across social platforms.
What once involved neatly structured spreadsheets or databases has grown into something far larger and more complex. One challenge quickly becomes clear. Not all data looks the same, behaves the same, or needs to be analyzed the same way. Rather than treating everything as one giant mass of information, professionals recognize that there are different types of big data with different characteristics, storage needs, and analytical approaches.
The Three Main Types of Big Data
Most data professionals recognize three primary types of big data: structured, semi-structured, and unstructured data.
In most environments, these formats appear side by side. A company may store transaction tables in a relational database, receive semi-structured system logs from applications, and accumulate large volumes of unstructured material such as documents, images, or customer messages. Recognizing the differences between each type helps practitioners determine how each one is handled.
Structured Data
Structured data is the form most people imagine when they think about databases. It is organized into clearly defined rows and columns, where every entry follows the same format.
A table that records customer purchases, for example, might include fields for customer ID, product code, purchase amount, and date. Each record fills those fields in the same order, which allows computers to store, search, and analyze the information very quickly.
In structured data, the structure is fixed; therefore, systems can retrieve specific values almost instantly. This reliability is why structured data is crucial to many operational systems. Most enterprise reporting, accounting platforms, and inventory systems rely on structured databases that are queried using languages such as SQL.
The strength of structured data is precision. When the format is predefined, everyone knows exactly where information is stored and how to retrieve it. The limitation is that this rigidity leaves little room for variation. If a new type of information needs to be captured, the database schema often has to be redesigned first. Systems built around strict tables can also become difficult to expand as the volume of data grows.
Examples and Use Cases of Structured Data
Many industries rely on this format to track transactions, records, and measurements with high accuracy.
Common examples include:
- E-commerce transactions: Order IDs, product SKUs, prices, timestamps, and shipping details stored in relational tables that support inventory management and sales reporting.
- Banking systems: Account balances, deposits, withdrawals, and transaction histories stored in structured databases that require strict consistency.
- Healthcare records: Demographic information, billing codes, diagnostic classifications, and appointment histories in electronic health record systems.
- Manufacturing quality control: Numerical measurements from production lines stored in databases that trigger alerts when values fall outside acceptable ranges.
- Streaming platform activity: Viewing events that record the title watched, device used, start time, and playback duration so companies can analyze patterns across millions of users.
Semi-Structured Data
Semi-structured data occupies the middle ground between rigid tables and completely free-form information. It contains markers that provide organization, but still do not fit neatly into rows and columns. These markers usually appear as tags, attributes, or key–value pairs that label pieces of information and give them context.
Imagine a customer profile stored as a small document rather than a row in a table. One entry might include a name, email address, preferred language, purchase history, and marketing preferences. Another entry might include additional fields such as loyalty status or shipping instructions. The structure is flexible, yet the labels make it possible for software to understand what each piece of data represents.
This flexibility is useful when different systems need to exchange information. A mobile application, a web service, and a payment platform may all store customer details slightly differently. Semi-structured formats allow these systems to share data without requiring an identical table structure on both sides.
Common Formats and Technologies for Semi-Structured Data
Semi-structured data is usually stored and exchanged through document-style formats. These formats attach labels to each piece of information, which helps systems interpret the data even when the structure varies between records.
Common formats and technologies include:
- JSON (JavaScript Object Notation): Uses key-value pairs and nested objects to represent information. It is the most widely used format for APIs and modern web applications because it is lightweight and easy for both humans and machines to read.
- XML (eXtensible Markup Language): Uses descriptive tags to wrap data elements. XML is often used in enterprise systems and regulated industries where structured validation is required.
- YAML: A human-readable format commonly used in configuration files and infrastructure management systems.
- MongoDB: A document-oriented database that stores JSON-like documents rather than fixed rows. This allows applications to add or modify fields without redesigning the database schema.
- Azure Cosmos DB: A globally distributed cloud database designed to store semi-structured documents and support flexible data models across multiple regions.
Unstructured Data
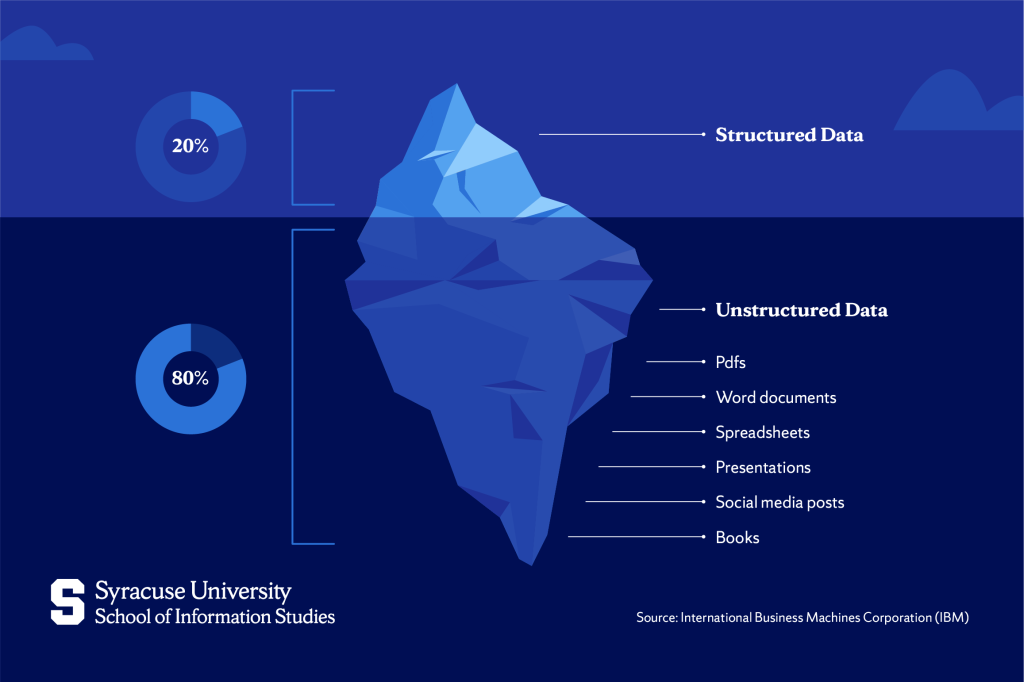
Unstructured data refers to information that has no predefined format at all. There are no fixed fields, no consistent schema, and no guarantee that two pieces of data will look alike. Instead, the content exists in forms created primarily for human interpretation: written text, images, audio recordings, videos, emails, chat messages, social media posts, and raw sensor outputs.
This category is enormous. A widely cited estimate suggests that unstructured data makes up roughly 80% of the world’s data. The challenge is that many traditional database systems were originally designed to manage structured information. So these databases cannot read an image, interpret a video, or understand the sentiment of a written comment. Extracting meaning from this material requires different technologies and analytical techniques.
Processing and Analyzing Unstructured Data
To work with and interpret unstructured data, some of the most common technologies and methods are:
- Natural Language Processing (NLP): Analyzes written or spoken text to detect topics, sentiment, and relationships between words. Used in customer feedback analysis, chatbots, document search systems, and social media monitoring.
- Computer Vision: Interprets images and video to identify objects, faces, scenes, or defects. Used in medical imaging, autonomous vehicles, security systems, and retail analytics.
- Machine Learning: Detects patterns across large collections of text, images, audio, or sensor data. Often used for fraud detection, recommendation systems, and predictive analytics.
- Data Lakes: Storage architectures that hold raw data in its original format. Unlike relational databases, data lakes can store documents, images, logs, and videos without forcing them into predefined tables.
- Apache Hadoop: A distributed computing framework that processes very large datasets by dividing them across clusters of servers.
- Apache Spark: A high-speed processing engine designed for large-scale analytics and machine learning on massive datasets.
Emerging Types of Big Data
The aforementioned three core categories describe how data is structured. In practice, however, modern systems also generate new forms of data defined by how quickly they arrive and how they are produced. These emerging types introduce new technical challenges because the information often appears continuously and at a very large scale.
Common examples include:
- Streaming data: Information generated continuously and processed immediately as it arrives. Examples include stock price updates, credit card transactions, and real-time fraud detection alerts.
- IoT sensor data: Measurements produced by connected devices such as factory machines, smart thermostats, delivery vehicles, and wearable health trackers. These devices send constant streams of readings such as temperature, location, or movement.
- Clickstream data: Records of how users interact with a website or mobile app. Each page view, button click, search query, or scrolling action creates a data point that shows how people navigate a digital service.
These emerging forms add a real-time dimension to information systems, where data is processed continuously rather than analyzed only after it has been stored.
Importance of Understanding Big Data Types
Understanding the different types of big data has clear strategic value for businesses, as it guides the approaches used and outcomes generated.
Recognizing the type of data being generated helps organizations with technology selection. Each data type works best with systems designed for its structure and scale. Transaction records rely on relational databases that support fast queries and reporting. Document-style data often sits in flexible storage systems designed for changing structures. Continuous streams from devices or online activity require tools that process events as they arrive. Identifying the data type early helps organizations invest in infrastructure that fits the information they collect.
Understanding data types also supports governance and regulatory oversight. Financial transactions, healthcare records, communications data, and operational logs each carry different legal obligations. Classifying information according to its type helps organizations apply appropriate access rules, monitoring procedures, and retention policies.
Clear categorization also improves coordination between technical and business teams. Technical teams design storage systems, analysts interpret datasets, and decision-makers rely on the results. When everyone understands the nature of the data involved, teams can align their work around the same assumptions and expectations.
From a strategic perspective, recognizing the types of big data allows organizations to draw insight from multiple sources at once. Operational records reveal measurable activity, behavioral data shows how people interact with systems, and device-generated streams capture conditions in real time. When these sources are understood and combined carefully, they provide a broader view of operations, customers, and performance.
Closing Thoughts on Big Data
Structured, semi-structured, and unstructured data each represent a fundamentally different challenge and, at the same time, a different opportunity. The organizations that understand these distinctions can manage their data more efficiently, ask better questions, build more resilient infrastructure around it, and turn the data into a genuine competitive asset.
The shift happening now is that the boundaries between these types are becoming more fluid. The professionals who thrive in this environment are the ones who can work fluidly across all three types and who understand which tools, governance models, and analytical approaches each one demands.
If you want to build the skills to work with data at this level, the Applied Data Science degree at Syracuse University’s iSchool prepares you to analyze different types of data and work with the tools used across modern data environments.
FAQ’s
Can semi-structured data be converted into structured data?
Yes. Through processes such as schema-on-read or ETL (extract, transform, load), semi-structured formats like JSON or XML can be parsed and loaded into relational tables. This approach works best when the data contains relatively consistent fields.
What are the 5 types of big data?
Most discussions begin with three core categories: structured, semi-structured, and unstructured data. Many practitioners also recognize streaming data and IoT sensor data as additional types because they introduce continuous, real-time data generation.
What trends are shaping the future of big data?
Several developments are influencing how organizations manage and analyze large datasets. These include real-time streaming architectures, artificial intelligence systems that analyze text, images, and video, the expansion of cloud-based data lakes, and increasing regulatory expectations around data governance and privacy.
Are there any challenges in managing semi-structured data?
Yes. Organizations often face inconsistent schemas across data sources, version changes when data formats evolve, and additional processing requirements to interpret tags and metadata at scale.
How do businesses decide which type of big data to focus on?
The choice depends on the question the organization is trying to answer. Operational reporting and financial analysis rely heavily on structured records. Customer experience analysis often uses unstructured signals such as feedback or interactions. Real-time monitoring systems rely on streaming data from transactions, devices, or digital platforms.