
Key Takeaways
- Data wrangling refers to a crucial process of preparing data for analysis.
- It involves several steps, such as data discovery, cleaning, structuring, transformation, and more.
- Data wrangling is important because it guarantees that the data used for analysis is accurate and consistent.
There is a common misconception that data analysis is primarily about running statistical algorithms on high-performance data engines. While it’s true that these algorithms are indeed important, they represent only one of the final steps in a much longer and more complex process.
A large portion of an analyst’s time is dedicated to wrangling the data. Data wrangling is needed to ensure that the raw data is in a format that can be analyzed. Without this part of the process, even the most advanced algorithms would struggle to generate meaningful and useful insights.
What Is Data Wrangling?
Data wrangling transforms and cleans data to make it suitable for further analysis through actions such as combining data from various sources and handling missing or inconsistent data.
Data wrangling is distinct from data cleaning, which primarily addresses the accuracy and integrity of the data, and ETL (Extract, Transform, Load), which is a broader process focused on moving and transforming data between systems.
Think of data wrangling as preparing ingredients for a recipe. You start with raw ingredients, similar to how data wrangling begins with data from various sources. The process of chopping, washing, and seasoning those ingredients corresponds to the steps of wrangling—getting everything ready before you cook (or analyze) it.
A Step-By-Step Data Wrangling Process
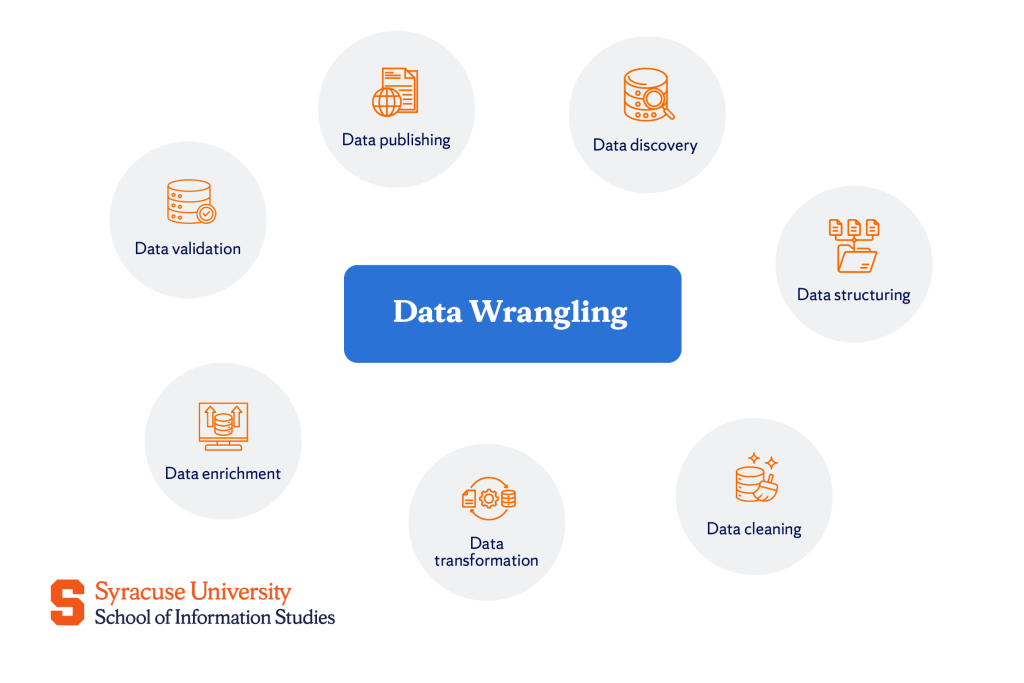
Data wrangling consists of multiple interdependent steps that transform raw data into a structured, clean, and usable format. Therefore, all aspiring data analysts must understand the following:
Data discovery
Data comes from various sources: APIs, databases, spreadsheets, and even real-time sensors. Sometimes, you get it from your system, like your company’s customer database, whereas other times, you’ll need to collect it from external sources, such as public datasets online.
The first step of data wrangling, once the data is collected, focuses on understanding the data. In the data discovery phase, you explore the data’s structure and quality to identify potential issues that may need to be addressed in later stages.
This step often involves profiling and visualization to better understand the distribution, relationships, and any inconsistencies or missing values within the data, which sets the foundation for effective cleaning and transformation in subsequent steps.
Data structuring
Data structuring involves reshaping the data, pivoting tables to rearrange rows and columns, or standardizing formats (e.g., ensuring that all dates are formatted the same way).
Data might be organized into separate tables for products and customers, and then these tables can be joined based on common fields, like product ID or customer ID.
Data cleaning
After the data is collected and structured, the next step is cleaning. Data cleaning addresses common issues like missing values, duplicate entries, and inconsistent formats.
For example, a dataset containing names might have variations in spelling (e.g., “Jon” and “John”). Missing values, such as empty cells in critical fields (e.g., missing dates or customer details), must also be dealt with.
Duplicate data is also something to be wary of as it can alter analysis and, therefore, must be removed. The goal during this whole process is to standardize and correct all inconsistencies in the data to prepare it for further analysis.
Data transformation
Data transformation can be achieved through different techniques that, in one way or another, modify the data and prepare it for detailed analysis.
One such technique is normalization, where data is adjusted to a common scale. For example, if you have data with varying ranges, like age and income, normalization would be used to bring these variables to a comparable scale, typically between 0 and 1. This makes them easier to analyze.
Another common transformation technique would be encoding categorical variables so that non-numeric data, such as “Yes” or “No” answers, are converted into numerical values. This is particularly useful for machine learning algorithms, as they often require numerical input to make predictions.
Data enrichment
Data enrichment refers to the step in data wrangling when existing datasets are enhanced by adding new information or attributes that provide deeper insights.
One common approach to this is merging datasets from multiple sources, like customer transaction data with demographic information, in order to create a more comprehensive dataset. Another aspect of data enrichment is adding new attributes. This could mean creating new columns or fields based on the existing data.
Data validation
Before you can begin with data analysis, it’s important to validate the data’s accuracy and integrity. This implies checking for any errors or inconsistencies that might affect the analysis.
For instance, data validation might involve confirming that all phone numbers follow a specific format or that there are no anomalies, like impossible values (e.g., negative ages or sales exceeding possible limits).
Data publishing
Data publishing is the final step in data wrangling. This is the stage when the cleaned, structured, and transformed data is shared or made available for use.
During data publishing, the data is often exported into formats suitable for different platforms or applications, such as CSV files, Excel spreadsheets, databases, or even APIs. It may also involve creating reports or dashboards that present the data in an accessible and actionable way for the intended audience.
Data Wrangling Tools & Techniques
Since data wrangling is a multi-step process, it’s necessary to use the right tools and techniques for each task. Depending on the task’s complexity and the user’s skill level, some of them include:
Manual methods
Manual methods in data wrangling are quite common, especially in smaller organizations when it comes to dealing with less complex tasks or when working with smaller datasets. Many individuals, particularly those who may not have programming skills, rely on tools like Excel and SQL for data wrangling because they are accessible and intuitive.
However, while manual methods are useful for simpler or smaller-scale tasks, they are typically not as efficient, scalable, or reliable for larger datasets or more complex data manipulations.
Programming tools
For more advanced wrangling tasks, programming languages like Python and R are preferred due to their flexibility and powerful libraries. In Python, the Pandas and NumPy libraries are particularly well-suited for handling large datasets and performing complex transformations.
Pandas, for instance, provide functions to handle missing data, filter and merge datasets, and perform mathematical operations. R, especially with the tidyverse collection of packages, is similarly effective, offering tools to manipulate, visualize, and model data.
These programming languages are essential for handling larger datasets and more intricate wrangling processes.
No-code & automation tools
For those who are not yet comfortable with coding, no-code tools like Trifacta, Alteryx, and OpenRefine provide user-friendly interfaces for data wrangling.
These tools allow users to clean, transform, and enrich data through intuitive drag-and-drop actions, making them accessible for business analysts, marketers, or anyone needing to prepare data without programming skills. They also offer automated workflows that can speed up tasks like filtering data, reshaping datasets, and generating reports.
AI-powered wrangling tools
AI-powered tools like DataRobot and Apache Spark ML are using machine learning to automate parts of the wrangling process, such as identifying patterns in the data and recommending transformations.
These tools make data wrangling easier by automatically suggesting ways to improve the quality of the data, detect anomalies, and streamline repetitive tasks. By utilizing AI, these tools can even learn from past decisions and adapt to new data trends, providing more intelligent and accurate wrangling suggestions over time.
Importance of Data Wrangling in Data Science & Business
Data wrangling sets the foundation for successful data analysis. Without it, raw data remains unstructured, inconsistent, and unreliable, thus making it virtually impossible for analysts to extract meaningful insights.
In machine learning, this process is critical because the quality of the data directly impacts the performance of models. It guarantees that algorithms learn from accurate and relevant information, which is necessary for reliable predictions.
On top of that, wrangling eliminates errors in datasets and prevents flawed analysis, ensuring that business decisions are based on trustworthy data.
Best Practices for Efficient Data Wrangling
To further improve the process of wrangling data, analysts can automate repetitive tasks using scripts or tools. This would help them save time and also make the process more efficient.
Another helpful practice would be keeping a log of the changes made to the data. So, they would have to record every transformation so that the process can be easily reviewed or repeated if needed.
Using version control for datasets would also help them track changes and even go back to earlier versions when necessary. Incorporating these practices in one’s work as an analyst would help make the whole process of data wrangling more organized and accurate.
Emerging Trends in Data Wrangling
According to GlobeNewswire’s latest report, the global data wrangling market is expected to reach $7.6 billion by 2031, growing at a compound annual growth rate (CAGR) of 13.9%. This growth is driven by the increasing complexity and volume of data from sources like IoT devices, social media, and cloud applications.
According to the report, the key trends shaping the data wrangling industry include:
- Self-service data wrangling tools, which allow non-technical users to prepare and transform data on their own
- Cloud-based solutions that provide scalable, flexible, and cost-effective options for managing data
- The increasing use of AI and machine learning to automate and improve data wrangling processes
- Automation of repetitive tasks and integration of diverse data sources
- Growing focus on data governance and compliance with regulations
- Demand for real-time analytics
Final Reflections on Data Wrangling
There’s more to effective data wrangling than just having clearly defined workflows or an understanding of the distinct steps involved. It’s about mastering the right tools and technologies, as well as understanding the underlying principles that drive successful data wrangling, so you can best go through each of those steps and prepare it for meaningful analysis.
This knowledge is something that can be developed through formal education. At Syracuse University’s iSchool, our Bachelor’s Degree in Data Analytics offers an excellent foundation in all areas of data analytics, including data wrangling, equipping you with the skills to handle complex datasets efficiently. We also offer a minor in Applied Data Analytics, which allows you to apply data-driven insights to your primary field of study.
Much like how data wrangling prepares data for use in more advanced analysis processes, our programs prepare you to leverage data for actionable insights that can propel your future career.
Frequently Asked Questions
What is the difference between data wrangling and data cleaning?
Data wrangling is the broader process that encompasses various stages of preparing data for analysis. Cleaning is one of those stages that focuses solely on identifying and correcting any issues with the data, like removing duplicates, fixing errors, or dealing with incomplete information.
What are the key steps in a typical data wrangling workflow?
In a typical data wrangling process, you start with data collection, followed by structuring the data to make it usable, cleaning it to remove or fix issues, validating its integrity, and finally enriching it by adding additional data or context before publishing it for use.
SQL vs. Python for data wrangling?
SQL is fantastic for managing and querying large sets of structured data. On the other hand, Python is much more versatile, offering a variety of libraries like Pandas and NumPy, which provide powerful tools for more complex data manipulation, automation, and analysis.